今回は過学習を防ぐ内容となります。
過学習(Overfitting)
🔷 定義:
- モデルが訓練データに対して過剰に適合しすぎて、新しいデータ(テストデータ)にうまく対応できない状態。
- 精度は高いのに、汎化性能(新しいデータへの対応力)が低い。
🔧 原因:
- モデルが複雑すぎる(層が多い、パラメータが多い)
- 特徴量が多すぎる
- データが少ない
- ノイズや外れ値まで学習してしまう
🎯 対策:
- アンサンブル学習(ランダムフォレストなど)
- 正則化(ラッソ・リッジ回帰など)
- データ増強
- 特徴量選択
ラッソ回帰
🔷 定義:
- 通常の線形回帰に**L1正則化(重みの絶対値の和のペナルティ)**を加えた手法。
🔢 目的関数:

✅ 特徴:
- 不要な特徴量の重みを0にすることがある(=変数選択ができる!)
- モデルのスパース化(シンプルに)に役立つ。
- 高次元データや特徴量が多いときに効果的。
リッジ回帰
🔷 定義:
- 通常の線形回帰に**L2正則化(重みの2乗のペナルティ)**を加えた手法。
🔢 目的関数:
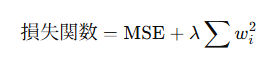
✅ 特徴:
- 重みの大きさを抑えることで、過学習を防ぐ。
- すべての特徴量をある程度使うが、重要度を調整。
- 特徴量の数 > データ数 のときにも安定する。
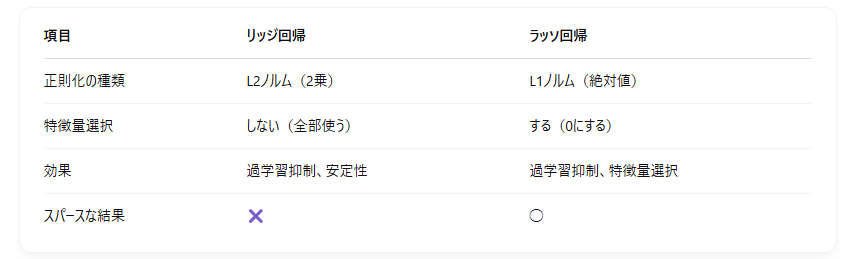
比較まとめ
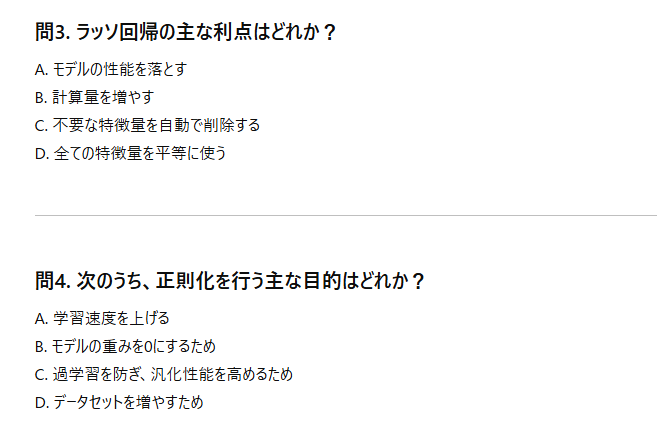
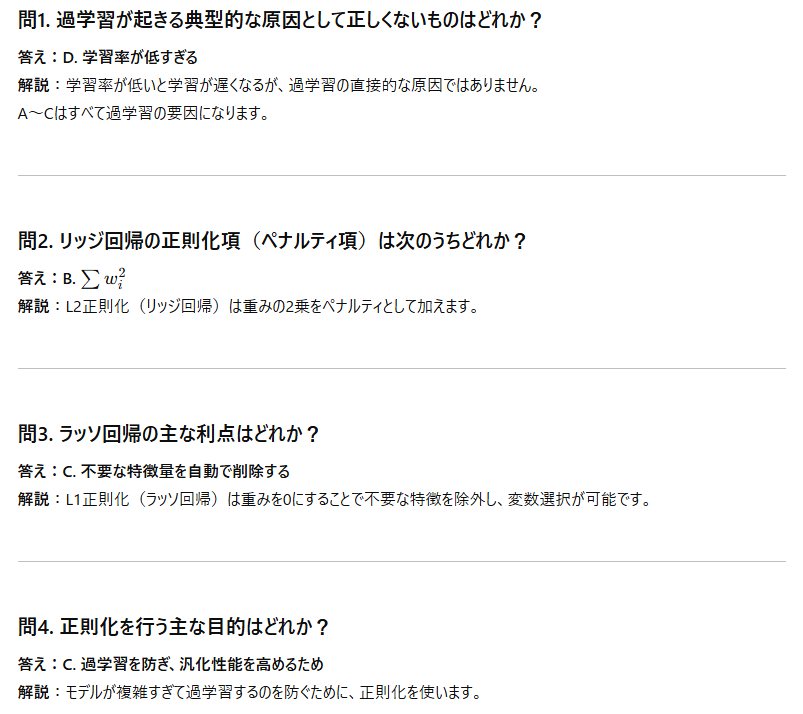
演習

↓
↓
↓
(解答)
参考資料
・データサイエンス数学ストラテジス